The issue has been resolved — the node is replying to requests normally.
To remove any potential future occurrence of that issue, a notification system for anomalies has been added and tested to the infrastructure stack.
The fix has been implemented (reloading the node stack).
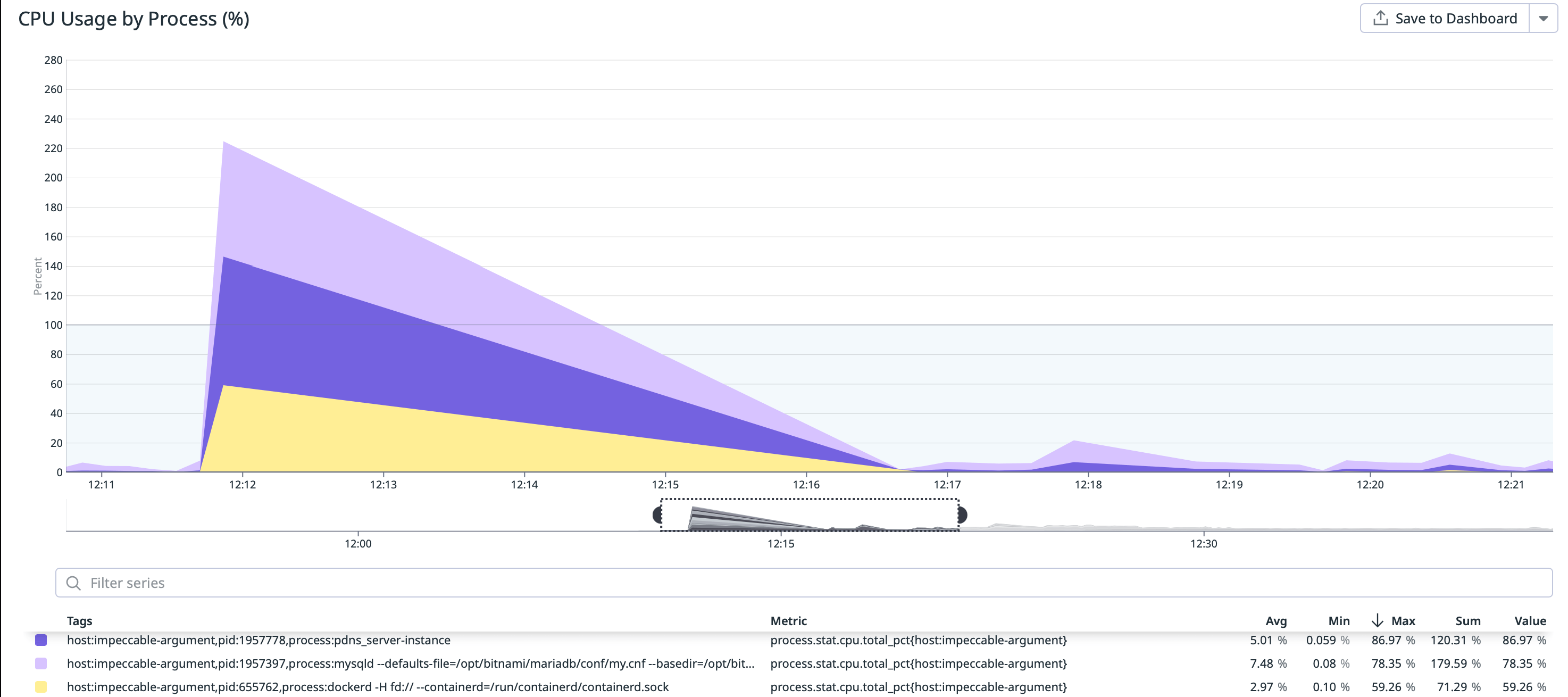
The abnormal CPU and disk usage has been identified at the Waterfall node.
Waterfall
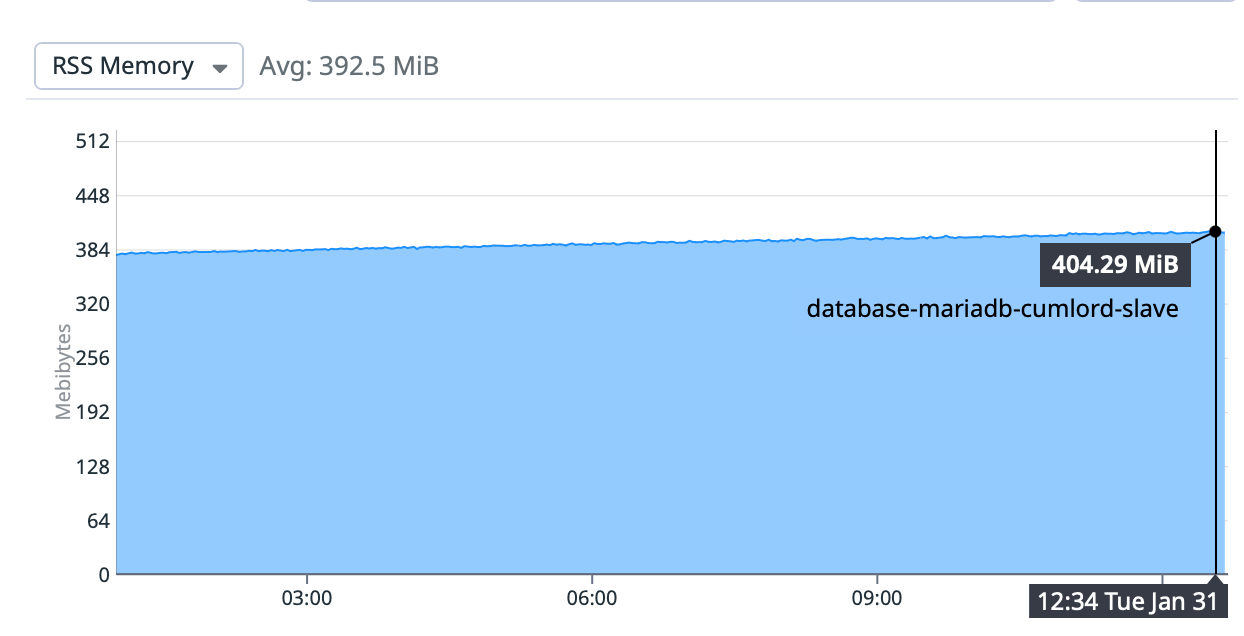
The root cause is declared to be a MariaDB process that leaked memory bit-by-bit over the past days leading to no RAM being left for other processes.
We are currently investigating this incident. As of now, seems like the Waterfall node is unresponsive to some requests.